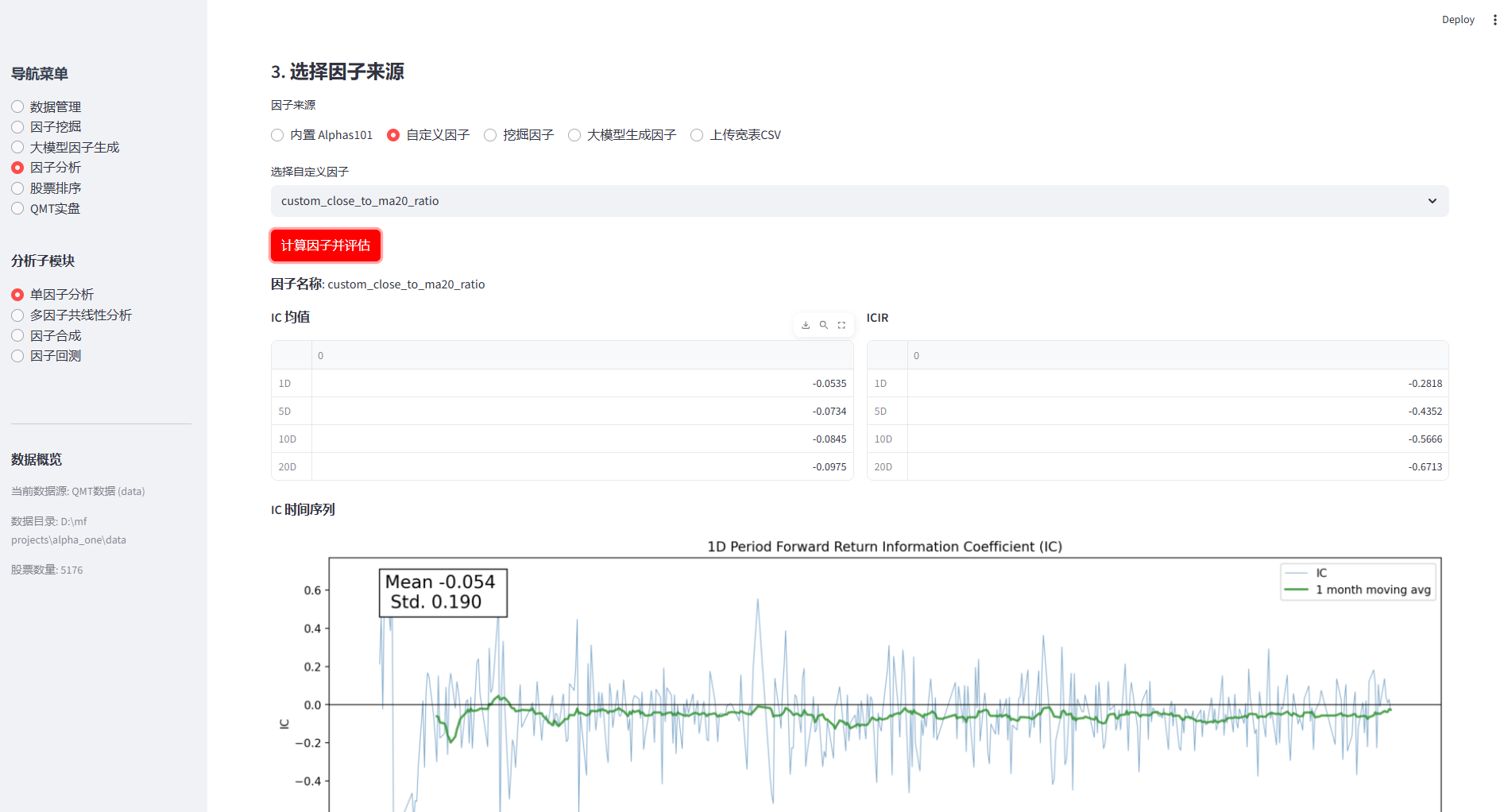
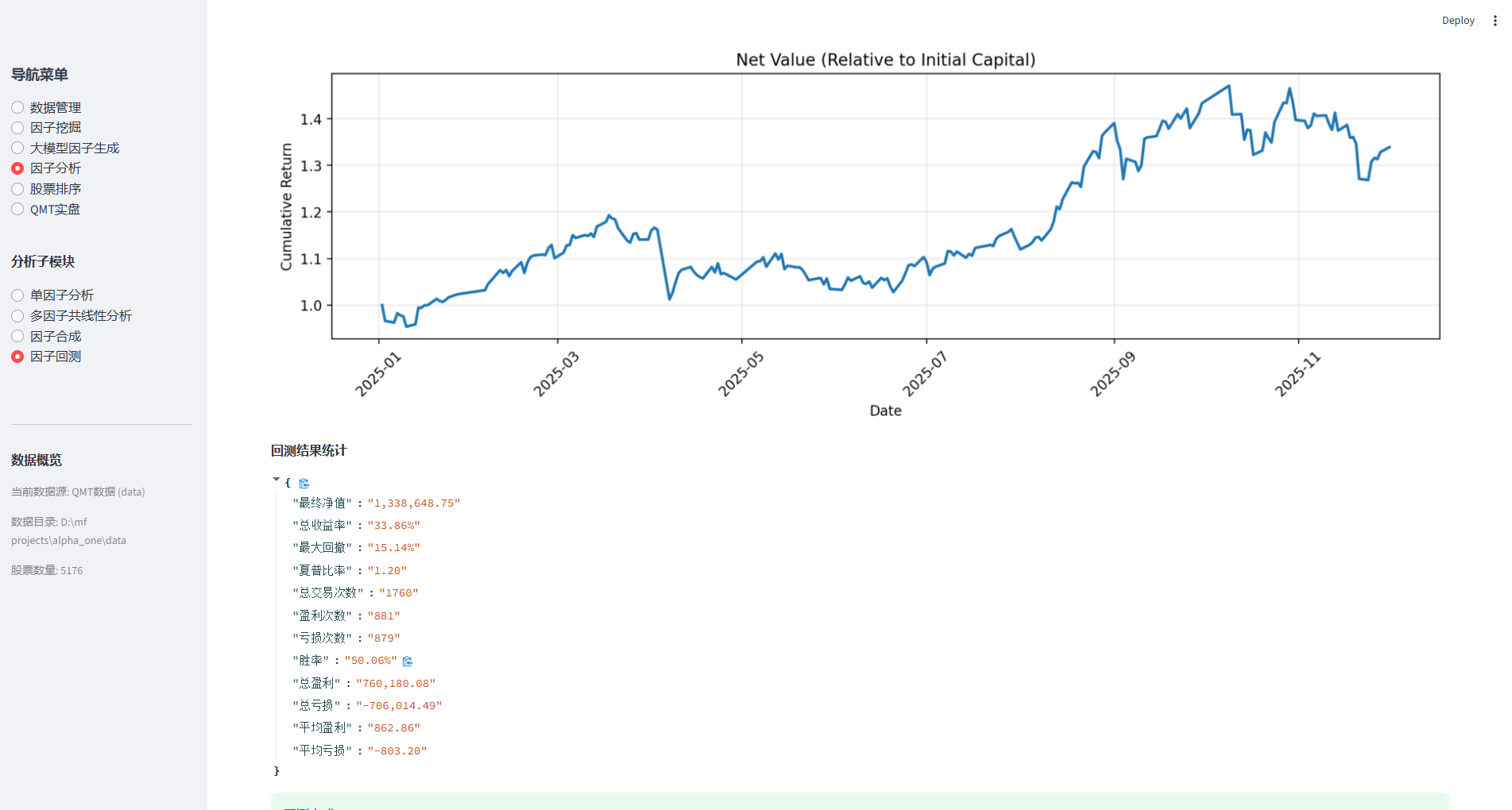
- 量化因子投资无非关注两个问题:什么样的因子有效,以及有效的因子何时变得无效。
- 之前我总是想着用最先进的模型来挖掘最有效的因子(强化学习,大语言模型等等),这正是学术界乐此不疲做的事情。后来发现我似乎搞错了重点。学术界这么做,因为这些看上去很fancy的模型可以发论文。如果一个模型、能够产生有效的因子,但是看上去太普通,是发不了论文的。
- 我目前采取的做法是用一个不那么fancy的模型,产生大量差不多的因子(可能几百上千个)然后从中选择10-20个左右的因子。把重点放在因子的有效选择上。然后每隔一段时间比如一个月,重新产生大量因子。再选择。
- 这样做的有好几个好处:10-20个因子的组合,相...
谈一谈我的量化实盘策略
389 views