前几天看了一下微软的Qlib框架,感觉也没有新的东西。到是提供了两个数据集alpha158和alpha360。于是看了几个例子,想看看Qlib 是如何利用alpha158 来做量化的。 其实Qlib的alpha158也好,国泰君安的alpha191因子也好,如果你仔细看一下这些因子的公式,我猜测大概率应该是根据类似遗传算法这种生成的。也就是说,这些个因子就是从原始的开盘价,收盘价,最高价,最低价,成交量等量价数据的基础上计算出来的。比如考虑alpha191 中的第一个因子alpha001的公式如下:
(-1 * CORR(RANK(DELTA(LOG(VOLUME),1)),RANK(((CLOSE-OPEN)/OPEN)),6)
我一开始接触量化最早使用的也是这些因子,但是我总认为,既然这些因子是在原始量价数据上二次加工的,难免会丢失一些信息,还不如直接用原始的数据。但是这几天看了微软的Qlib,也决定跑跑看这些个模型。但是发现joinquant 没有安装Qlib,但是提供了alpha191,于是我以alpha191 因子为例来写了个策略。具体思路如下:
- 先选取一个备选的股票池,比如全部消费类股票。
- 计算每一只股票的全部191 个因子 (我发现聚宽的alpha 函数运行非常慢,如果数据取太多,容易报超时错误)。
- 对模型进行回归训练,预测T+n 天之后的股价变化。(由于我担心特征太多,数据太少,就用了PCA保留了10个主要特征, 模型的话测试了Linearregression,lightgbm, SVR)
- 购入评分最高的5只股票。
- 每隔30天重新训练模型。
首先我们看一下聚宽的alpha函数返回的到底是个什么东西。

每一行都是一个训练样本,由于不同特征(alpha)之间量级不同,所以需要做归一化处理。由于聚宽上跑这个模型非常的慢,所以我只是测试了几个机器学习模型如linear regression, SVR 等。此外,PCA这边取了10,n取了10天。所有这些参数读者如果有兴趣都可以调一下看看效果如何。近一年的回测结果如下:
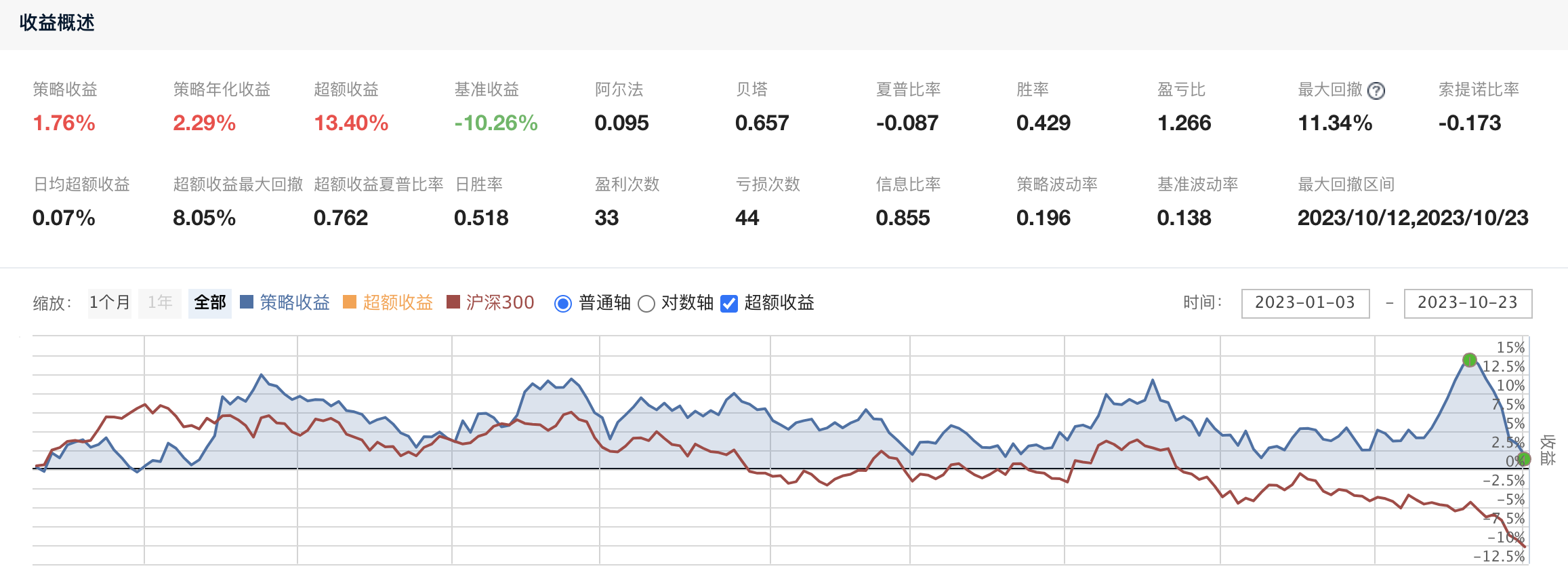
可以看到,策略年化只有2.29%,超额收益为13.40%(这里的比较基准为沪深300)。显然2.29%的年化一般是入不了投资者的眼的,而且这种情况还是我调了好几个参数之后才得到的结果。就我个人而言,我一直对这些量价因子持有偏见,也更倾向于使用基本面因子。
聚宽代码如下:
# 导入函数库
import jqdata
from jqlib.technical_analysis import *
from jqdata import *
from jqlib.alpha191 import *
import warnings
from datetime import date
import numpy as np
import pandas as pd
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LinearRegression
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from lightgbm import LGBMRegressor
import time
import datetime
from datetime import date
# 初始化函数
def initialize(context):
# 滑点高(不设置滑点的话用默认的0.00246)
set_slippage(FixedSlippage(0.02))
# 沪深300
set_benchmark('000300.XSHG')
# 用真实价格交易
set_option('use_real_price', True)
set_option("avoid_future_data", True)
# 过滤order中低于error级别的日志
log.set_level('order', 'error')
warnings.filterwarnings("ignore")
# 选股参数
g.freq_model = 30
g.freq_trade = 10
g.count = 0
g.position = 1 # 仓位
g.stock_num = 5
g.period = 10
g.training_days = 30
# g.model = train_model(context)
# 手续费
set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0001, close_commission=0.0001, min_commission=5), type='stock')
# 设置交易时间
run_daily(my_trade, time='14:45', reference_security='000300.XSHG')
def train_model(context):
curr_data = get_current_data()
yesterday = context.previous_date
# 过滤次新股
by_date = yesterday - datetime.timedelta(days=365*3) # 三年
initial_list = get_all_securities(date=by_date).index.tolist()
#initial_list = get_all_securities().index.tolist()
# 零售,可以换成其他
initial_list = get_industry_stocks('HY005')
# 过滤当日涨跌停,st,科创板,停牌
stock_list = filter_limit_stock(context, initial_list)
stock_list = filter_st_stock(stock_list)
stock_list = filter_kcb_stock(stock_list)
stock_list = filter_paused_stock(stock_list)
# log.info('初始股票数量:%d' % len(initial_list))
end_date = yesterday
start_date = end_date - datetime.timedelta(days=g.training_days) # 取前面d 天的数据来训练模型,如果d太大会报超时错误。
df = get_price(stock_list, start_date=start_date,
end_date=yesterday, frequency='daily', fields=None,
skip_paused=False, fq='pre', panel=False)
df['y'] = df.groupby(['code'])['close'].pct_change(periods=g.period)
times = df.time.unique()
X_y = []
for i in range(len(times) - 1 - g.period):
end_date = str(times[i])[:10]
df_alpha = alpha(stock_list,benchmark='000300.XSHG',end_date=end_date, fq='pre')
df_alpha['y'] = (df[df['time'] == times[i+1 + g.period]]['y'].values)
df_alpha = df_alpha.fillna(0)
X_y.append(df_alpha)
result = pd.concat(X_y)
result = result[result['y'] != 0]
X_features = result.drop('y', axis=1)
y_labels = result.y
X_features = X_features.replace((np.inf, -np.inf, np.nan), 0)
y_labels = y_labels.replace((np.inf, -np.inf, np.nan), 0)
pcr = make_pipeline(StandardScaler(), PCA(n_components=10), LinearRegression())
#pcr = make_pipeline(StandardScaler(), PCA(n_components=10), SVR(C=1.0, epsilon=0.2))
#pcr = make_pipeline(StandardScaler(), PCA(n_components=10),
# LGBMRegressor(objective='regression', num_leaves=31))
# Model
pcr.fit(X_features, y_labels)
return pcr
# 开盘时运行函数
def my_trade(context):
# 获取选股列表并过滤掉:st,st*,退市,涨停,跌停,停牌
if g.count % g.freq_model == 0:
log.info("day:", g.count)
g.model = train_model(context)
if g.count % g.freq_trade == 0:
log.info("count:", g.count)
check_out_list = get_stock_list(context)
log.info('今日自选股:%s' % check_out_list)
adjust_position(context, check_out_list)
g.count += 1
# 2-2 选股模块
def get_stock_list(context):
# type: (Context) -> list
curr_data = get_current_data()
yesterday = context.previous_date
# 过滤次新股
by_date = yesterday - datetime.timedelta(days=365*3) # 三年
initial_list = get_all_securities(date=by_date).index.tolist()
#initial_list = get_all_securities().index.tolist()
# 消费,可以换成其他
initial_list = get_industry_stocks('HY005')
# 过滤当日涨跌停,st,科创板,停牌
stock_list = filter_limit_stock(context, initial_list)
stock_list = filter_st_stock(stock_list)
stock_list = filter_kcb_stock(stock_list)
stock_list = filter_paused_stock(stock_list)
X_test = alpha(stock_list,benchmark='000300.XSHG',end_date=yesterday, fq='pre')
X_test = X_test.replace((np.inf, -np.inf, np.nan), 0)
pred_y = g.model.predict(X_test)
X_test['pred_y'] = pred_y
stocks_buy = X_test.sort_values(by=['pred_y'], ascending=False)[:g.stock_num].index.tolist()
return stocks_buy
# 过滤涨跌停股票
def filter_limit_stock(context, stock_list):
current_data = get_current_data()
holdings = list(context.portfolio.positions)
return [stock for stock in stock_list if (stock in holdings) or
(current_data[stock].low_limit < current_data[stock].last_price and
current_data[stock].last_price < current_data[stock].high_limit)]
# 过滤停牌股票
def filter_paused_stock(stock_list):
current_data = get_current_data()
return [stock for stock in stock_list if not current_data[stock].paused]
# 过滤ST及其他具有退市标签的股票
def filter_st_stock(stock_list):
current_data = get_current_data()
return [stock for stock in stock_list if not (
current_data[stock].is_st or
'ST' in current_data[stock].name or
'*' in current_data[stock].name or
'退' in current_data[stock].name)]
# 过滤科创板
def filter_kcb_stock(stock_list):
return [stock for stock in stock_list if not stock.startswith('688')]
#过滤模块-创业板
def filter_cyb_stock(stock_list):
return [stock for stock in stock_list if stock[0:3] != '300']
def adjust_position(context, buy_stocks):
#order_value(g.bond,context.portfolio.available_cash)
for stock in context.portfolio.positions:
if stock not in buy_stocks:
order_target(stock, 0)
position_count = len(context.portfolio.positions)
if g.stock_num > position_count:
value = context.portfolio.cash * g.position / (g.stock_num - position_count)
for stock in buy_stocks:
if stock not in context.portfolio.positions:
order_target_value(stock, value)
if len(context.portfolio.positions) == g.stock_num:
break